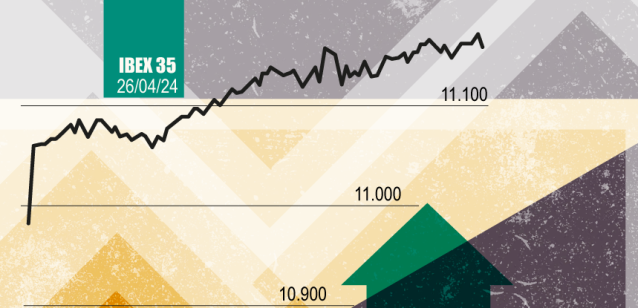
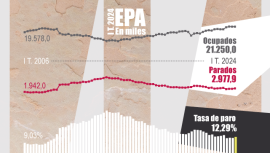
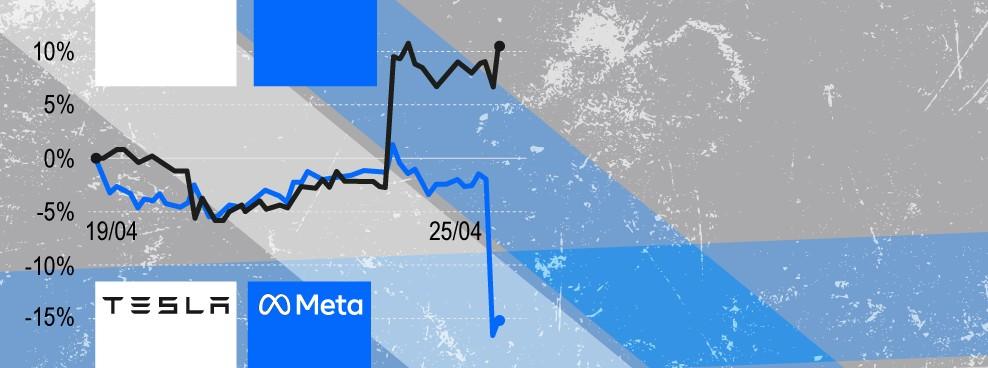
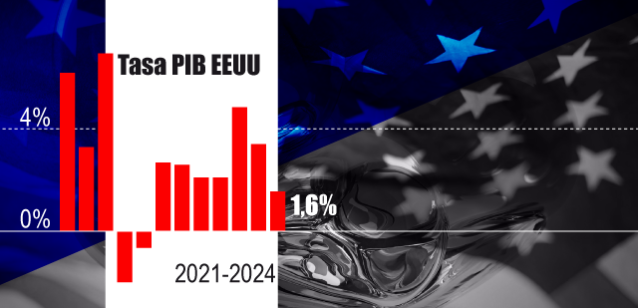
Declaración de objeciones
La UE teme que la fusión IAG-Air Europa limite la competencia del mercado aéreo
El ejecutivo comunitario alerta de que al llevarse a cabo la adquisición de la aerolínea de Globalia por parte del grupo hispano-británico, los clientes podrían sufrir una subida de los precios o una disminución de la calidad de los servicios.